本研究使用 RSNA Intracranial Hemorrhage Detection 競賽所提供的公開資料集,影像格式皆為 DICOM 的 CT 切片影像
影像為DICOM格式的CT影像,影像之間有序列關係,例如一位病患可能有多次檢查,每次檢查都有不同的序列影像,而每一序列之下會有多張連續影像。









除此之外,還提供了一份原始標籤檔案(.csv),每筆資料代表一個影像與出血類型的標註組合
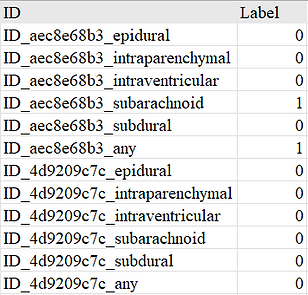
ID 欄位:
-
ID_ [影像檔案名稱]_[子類名稱]
-
子類名稱包括 :
Label 欄位:
-
1 表示該類型出血存在
-
0 表示無該類型出血
epidural(硬腦膜上出血)
intraparenchymal(腦實質內出血)
intraventricular(腦室內出血)
subarachnoid(蛛網膜下腔出血)
subdural(硬腦膜下出血)
any(是否有任一種出血)
資料前處理
為了將影像輸入深度學習模型,我們依照以下流程進行前處理:
1. RescaleSlope 與 RescaleIntercept:
將原始像素值轉換為臨床上具有物理意義的 Hounsfield Unit。HU 值能準確反映組織密度,以利後續處理。
2. 三通道窗位映射(Pseudo-RGB):
原始 DICOM 格式的頭部 CT 影像屬於單通道灰階影像,若僅以單一窗位顯示,容易導致部分病灶或結構細節被壓縮或忽略。因此,本研究採用多窗位通道融合策略,將每張影像以三種不同窗寬與窗位輸入,分別套用以下三組窗位參數:
Channel 1 → Brain window (WL=40, WW=80)
Channel 2 → Subdural window (WL=50, WW=130)
Channel 3 → Bone window (WL=600, WW=2800)
每一組窗位會將 HU 值依據設定範圍進行裁切與線性映射(縮放至 [0,1]),再於通道維度上堆疊成三通道影像 [H, W, 3],類似 RGB 影像結構。
3. Resize:
統一影像尺寸為 224×224 (ResNet50) 或是380×380 (EfficientNet-B3)
4. ToTensor:
將 PIL 影像轉換為 PyTorch 張量格式轉換(PIL→Tensor),並同時將像素值除以 255,將數值範圍標準化至 [0,1] 範圍。
5. Normalize:
根據整體訓練資料分佈,進行通道層級的標準化,使輸入數據具備零均值與單位方差,有助於梯度穩定與訓練收斂。
6. 影像 z 值正規化:
讀取每張影像的切片位置(Z 值),並將其正規化至 [0,1] 以供位置感知模型使用。將影像相關資訊整理成新的標籤檔案(.csv)。

資料增強
訓練前會將資料進行增強,目的是讓模型看到更多變形或不同亮度和對比度的樣本,提升模型對少數類別與小變化的泛化能力,以避免過擬合。本研究使用了以下幾種增強方法:
1. RandomHorizontalFlip:
隨機水平翻轉,使模型對圖像的左右方向不敏感,減少圖像方向帶來的偏見,防止過擬合。
2. RandomRotation:
透過隨機旋轉來模擬數據的多樣性,模擬圖像採集時輕微的角度偏差。
3. ColorJitter:
隨機改變圖像的亮度和對比度,模擬不同掃描儀或成像條件的變化。
4. Add Gaussian Noise:
增加輕微隨機噪聲,模擬真實世界的影像雜訊,增強模型的泛化能力。
5. Mixup:
將兩張隨機選取的影像及其標籤以權重 α=0.2 的比例線性混合,使模型學會更平滑的決策邊界。
6. TTA:
在驗證及測試時,對同一張影像做多種變換,例如水平翻轉、垂直翻轉、旋轉等,將多次預測取平均。目的是減少單一輸入的不穩定性,提高預測穩定度。
Conv3_x
Conv4_x
Conv5_x
Image Feature
2048 D
-
3-window CT (Brain/Subdural/Bone)
輸入影像
ResNet-50 Backbone
Conv1
Conv2_x
MLP Linear64
RELU
Concat
normalized
slice position
-
Joint feature
=[ visual + positional ]
-
Z_normalized ∈ (b, 1]
-
MLP structure: Linear (1→64) + ReLU
Fusion
FC
Sigmoid
-
learns cross-feature interactions
-
Liner → ReLU (+ Dropout)
-
independent probabilities (0~1)
for each class

評估指標
-
Precision (精確度): 用於量化在模型所有預測為正例的樣本中,實際為真陽性的比例,藉以評估模型避免誤報的能力。
-
Recall (召回率): 衡量所有真實正例的樣本中,模型能夠成功識別為正例的比例,藉以評估模型全面偵測病灶的能力。
-
F1 Score (F1 值): 此指標是精確度與召回率的調和平均數,提供了一個綜合衡量模型在兩者間達到平衡性能的單一評估標準。
-
Log Loss (對數損失): 評估模型預測機率與真實標籤之間的平均差異程度,其數值越低代表模型的預測結果越精確且更具信心。
Logits 與 Sigmoid 激活函數
本研究所採用之模型於最後一層輸出一組實值向量 z=[z1,z2,…,zK],稱為 logits。這些 logits 表示模型對各分類(或標籤)之「相對信心 (log‐odds)」。為將 logits 轉換為符合機率意涵的標籤預測值,本文對每一維 zj分別應用 Sigmoid 激活函數:

其中σ(⋅)將實數域映射至開區間(0,1),使 pj 可視為該標籤存在的機率。在多標籤二分類任務中,每張影像/樣本需獨立預測 K 個標籤,因此選用 Sigmoid 而非 Softmax,以保證各 pj 互不制約、可同時取高值。
後續訓練與評估階段,依據真實標籤 yj∈{0,1} 與預測機率 pj 計算對數損失 (log loss):
−[ ylog (p) + (1−y) log (1−p) ] 並依照任務設計予以加權平均,以作為最終性能指標。